
4 案例研究:ER损伤
4.1 简介
在过去的三个章节中,我向您介绍了一系列新概念。为了帮助理解他们,我们现在将浏览一个更丰富的Shiny应用程序,该应用程序探索了一个有趣的数据集,并将您迄今为止看到的许多想法整合在一起。我们将从Shiny之外进行一些数据分析开始,然后将其转化为应用程序,从简单开始,然后逐步添加更多细节。
在本章中,我们将使用vroom(用于快速读取文件)和tidyverse(用于一般数据分析)来补充Shiny。
1 | library(shiny) |
4.2 数据
我们将探索消费者产品安全委员会收集的美国国家电子伤害监测系统 (NEISS) 的数据。这是一项长期研究,记录了美国代表性医院中发生的所有事故。这是一个有趣的数据集,因为每个人都熟悉这个领域,每个观察都附有简短的叙述,解释事故是如何发生的。您可以在 https://github.com/hadley/neiss 了解有关此数据集的更多信息。
在本章中,我将只关注2017年的数据。这使得数据足够小(约10 MB),易于存储在git中(以及本书的其余部分),这意味着我们不需要考虑快速导入数据的复杂策略(我们将在本书稍后回到这些策略)。您可以在https://github.com/hadley/mastering-shiny/blob/master/neiss/data.R上看到我用于创建本章提取的代码。
如果你想把数据传到自己的电脑上,运行这段代码:
1 | dir.create("neiss") |
我们将使用的主要数据集是伤害数据集,其中包含约25万条观察记录:
1 | injuries <- vroom::vroom("neiss/injuries.tsv.gz") |
每行代表一起单次事故,有10个变量:
trmt_date是该人被送往医院的日期(不是事故发生的日期)。age、sex和race给出了发生事故的人的人口统计信息。body_part是身体受伤部位的位置(如脚踝或耳朵);location是事故发生的地方(如家庭或学校)。diag给出了伤害的基本诊断(如骨折或撕裂)。prod_code是与伤害相关的主要产品。weight是统计权重,给出了如果将此数据集按比例缩放到整个美国人口,遭受这种伤害的人数估计。narrative是关于事故如何发生的简短故事。
我们将将其与其他两个数据帧配对以获取更多上下文:products让我们可以从产品代码中查找产品名称,population让我们知道2017年美国每一种年龄和性别组合的总人口数。
1 | products <- vroom::vroom("neiss/products.tsv") |
4.3 探索
在我们创建应用程序之前,让我们先来探索一下数据。我们将从一款具有有趣故事的产品开始:649,“厕所”。首先,我们将提取与此产品相关的伤害:
1 | selected <- injuries %>% filter(prod_code == 649) |
接下来,我们将进行一些基本的汇总,查看与厕所相关的伤害的位置、身体部位和诊断。请注意,我用weight变量加权,这样计数可以解释为整个美国估计的总伤害数。
1 | selected %>% count(location, wt = weight, sort = TRUE) |
正如你可能预期的那样,涉及厕所的伤害最常发生在家里。最常涉及的身体部位可能表明这些伤害是跌倒造成的(因为头部和脸部通常不涉及日常厕所使用),而且诊断似乎相当多样化。
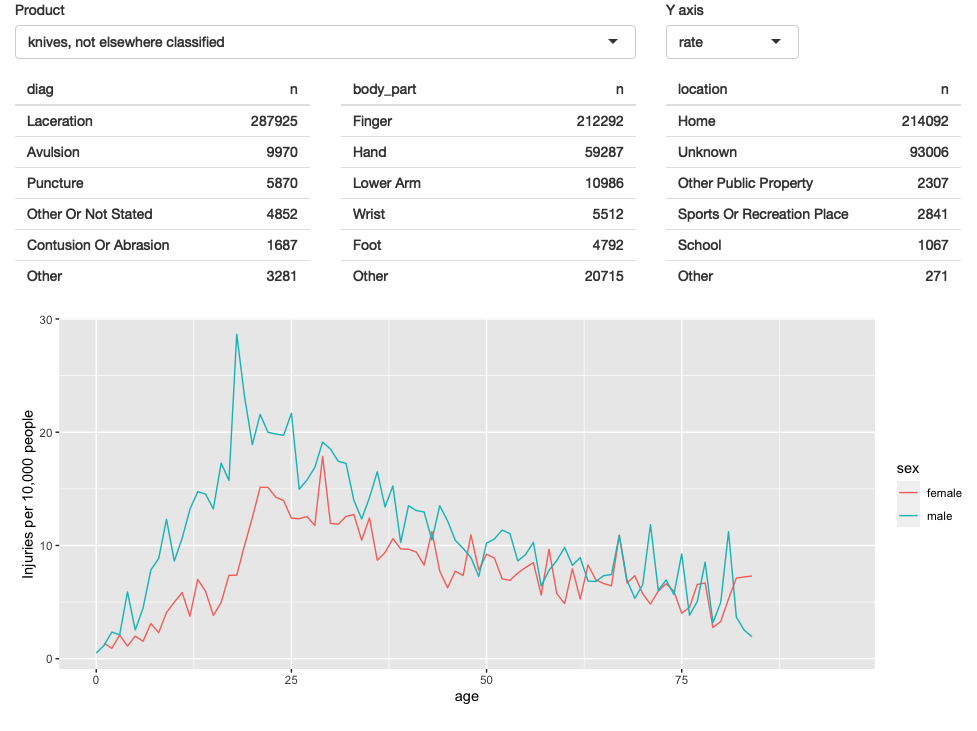
我们还可以探索年龄和性别之间的模式。这里我们有足够的数据,表格不是很有用,所以我做了一个图,图4.1,这使得图案更加明显。
1 | summary <- selected %>% |
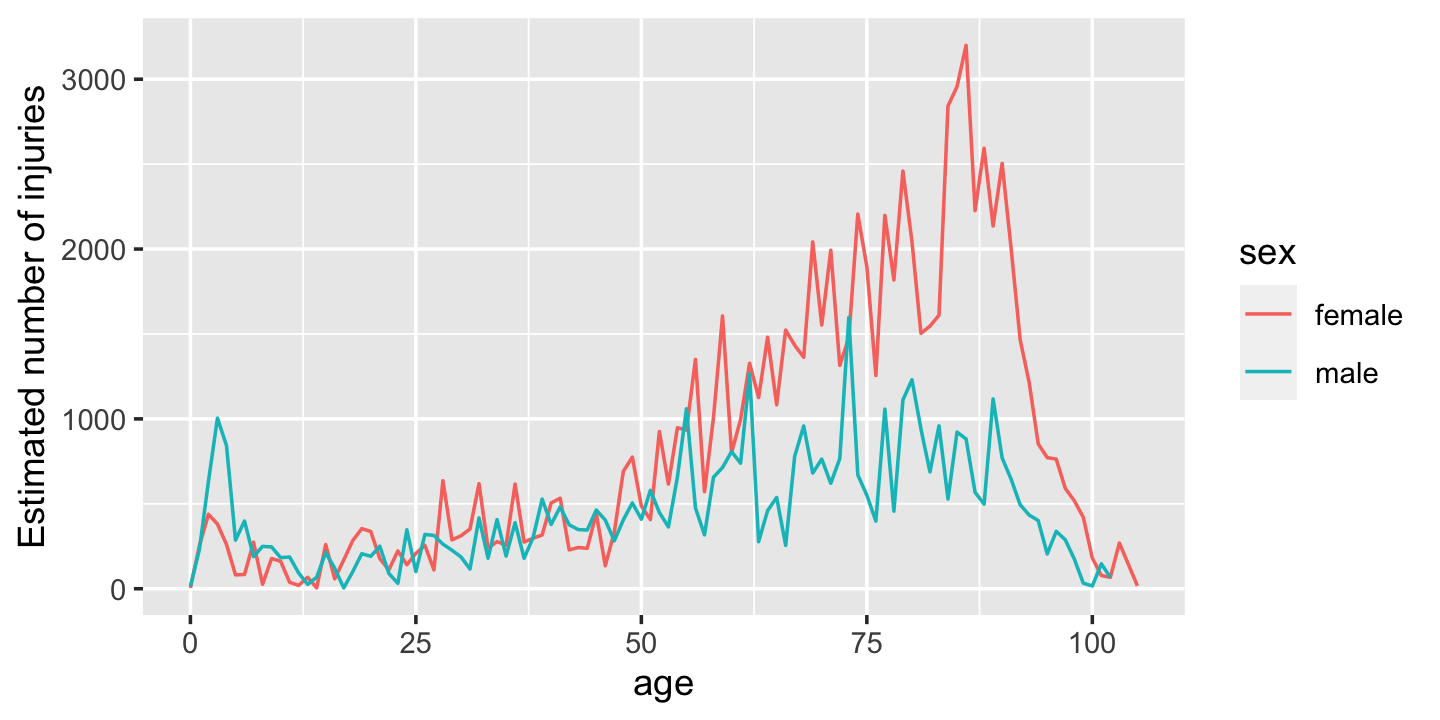
我们可以看到,小男孩在3岁时达到峰值,然后从中年开始有所增加(特别是对女性而言),在80岁以后逐渐下降。我认为峰值是因为男孩通常站着上厕所,而女性的增加是因为骨质疏松症(即,我怀疑男性和女性的受伤率相同,但更多的女性最终进入急诊室是因为她们骨折的风险更高)。
解释这种模式的难点在于,我们知道老年人比年轻人少,因此受伤的人口更少。我们可以通过将受伤人数与总人口进行比较并计算伤害率来控制这一点。这里我使用的是每10,000人的比率。
1 | summary <- selected %>% |
绘制比率图(图4.2),50岁以后的趋势明显不同:男女之间的差异要小得多,我们不再看到下降。这是因为女性往往比男性寿命更长,所以在老年时,更多的女性仍然活着并可能因厕所受伤。
1 | summary %>% |
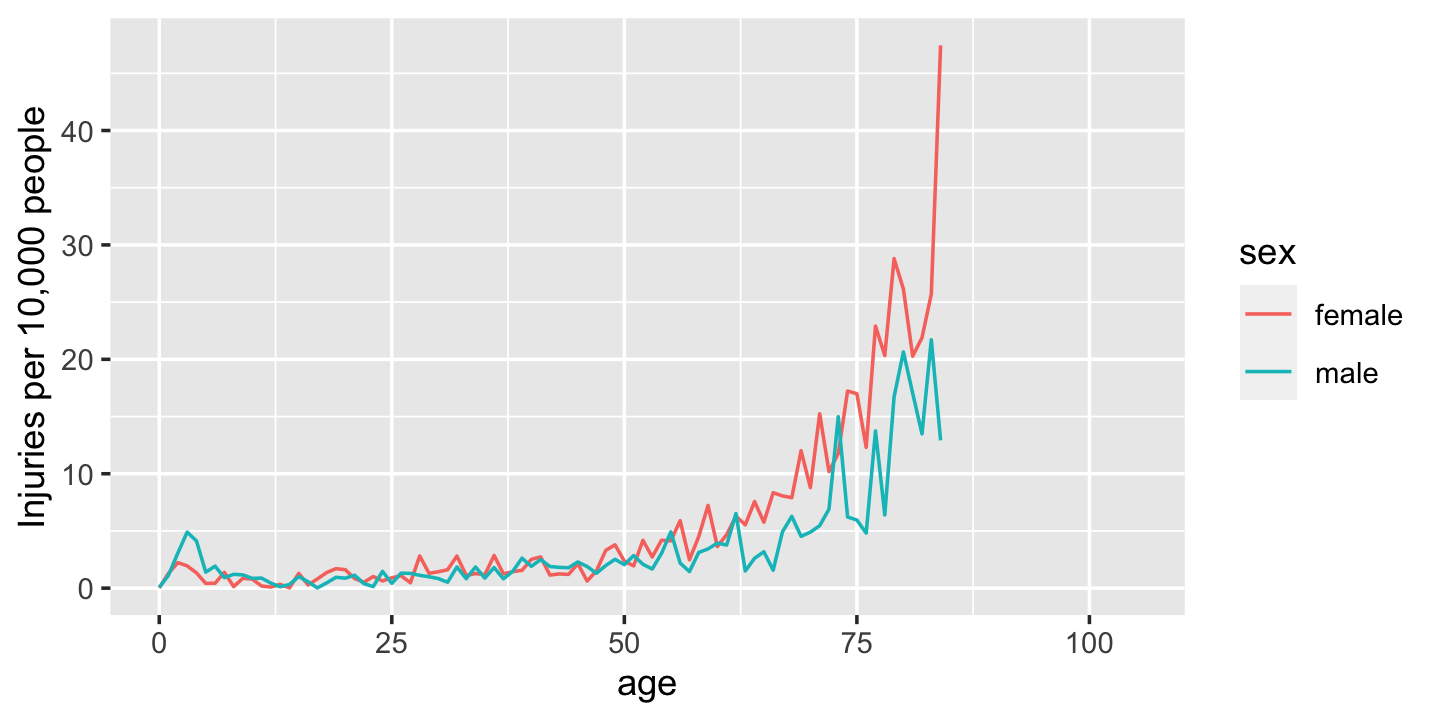
(注意,比率只到80岁,因为我找不到80岁以上年龄的人口数据。)
最后,我们可以浏览一些叙述。通过浏览这些叙述是一种非正式的方法,可以检查我们的假设,并产生新的想法以进一步探索。这里我随机抽取了10个样本:
1 | selected %>% |
对于一个产品进行了这种探索之后,如果我们能够轻松地对其他产品进行这种探索,而无需重新输入代码,那将是非常好的。所以让我们制作一个Shiny应用程序!
4.4 原型
在构建一个复杂的应用程序时,我强烈建议您尽可能从简单开始,这样您可以在开始进行更复杂的操作之前确认基本机制可以运行。在这里,我将从一个输入(产品代码)、三个表和一个图形开始。
在设计第一个原型时,挑战在于使其“尽可能简单”。在快速实现基本功能和为应用程序的未来做计划之间存在紧张关系。任何极端都可能很糟糕:如果你设计得太狭窄,你将在稍后花费大量时间重新设计你的应用程序;如果你设计得太严格,你将花费大量时间编写最终将被删除的代码。为了帮助找到平衡,我经常在代码之前用铅笔画一些草图来快速探索用户界面和反应图。
在这里,我决定将一行用于输入(考虑到在应用程序完成之前我可能会添加更多输入),一行用于所有三个表格(给每个表格4列,占12列宽度的1/3),然后一行用于图形:
1 | prod_codes <- setNames(products$prod_code, products$title) |
我们还没有谈论fluidRow()和column(),但你应该能够从上下文中猜测它们的作用,我们将在第6.2.3节回来讨论它们。另外请注意在selectInput() choices中使用setNames():它在用户界面中显示产品名称并返回产品代码到server。
server函数相对简单。我先将上一节中创建的selected和summary变量转换为反应式表达式。这是一个合理的通用模式:您在数据分析中创建变量以分解分析步骤,并避免多次重新计算,而Shiny应用程序中的反应式表达式起到相同的作用。
通常,在开始Shiny应用程序之前,花一些时间清理你的分析代码是一个好主意,这样你就可以在添加反应性的额外复杂性之前用常规R代码来考虑这些问题。
1 | server <- function(input, output, session) { |
注意,在这里创建summary反应式并不是严格必要的,因为它仅被一个反应式消费者使用。但是,将计算和绘图分开是很好的做法,因为这样可以使应用程序的流程更易于理解,并且将来更易于推广。
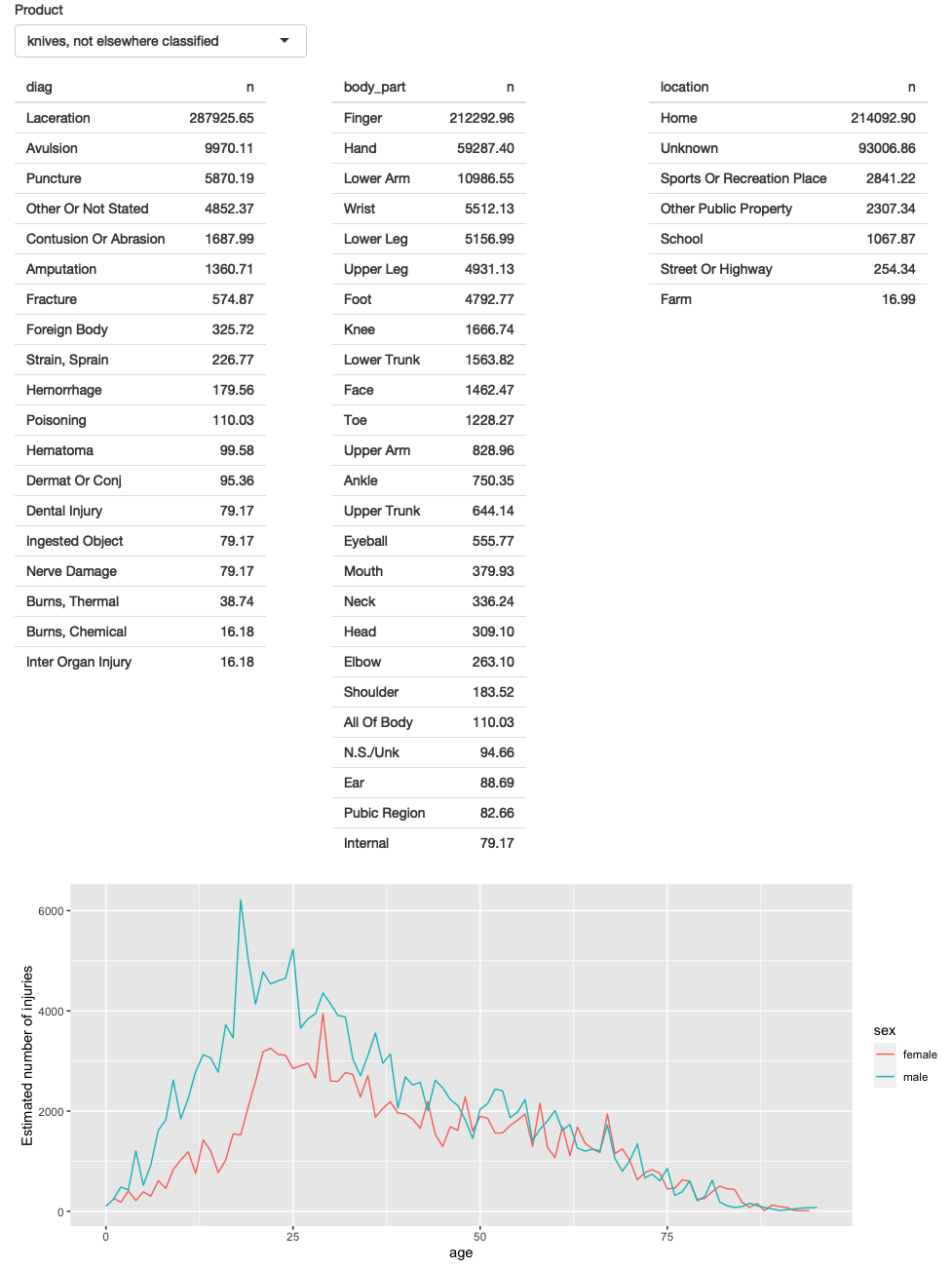
最终应用程序的屏幕截图如图4.3所示。您可以在此处找到源代码:https://github.com/hadley/mastering-shiny/tree/master/neiss/prototype.R,并尝试运行该应用程序的实时版本:https://hadley.shinyapps.io/ms-prototype/。
4.5 完善表格
既然我们已经将基本组件放置并运行,我们可以逐步改进我们的应用程序。这个应用程序的第一个问题是,它在表格中显示了很多信息,我们可能只想知道重点。为了解决这个问题,我们需要首先找出如何截断表格。我选择通过组合forcats函数来实现:我将变量转换为因子,按级别的频率排序,然后将前五个级别之后的所有级别都放在一起。
1 | injuries %>% |
因为我知道如何做到这一点,所以我编写了一个小函数来自动执行此操作,对任何变量。这里的细节并不是那么重要,但我们将在第12章中回到它们。您也可以通过复制和粘贴解决问题,因此如果代码看起来完全陌生,请不要担心。
1 | count_top <- function(df, var, n = 5) { |
接下来采用server函数:
1 | output$diag <- renderTable(count_top(selected(), diag), width = "100%") |
我做了另一个更改来改善应用程序的美观性:我强制所有表占据最大宽度(即填充它们出现的列)。这使得输出在美学上更加美观,因为它减少了偶然变化的数量。
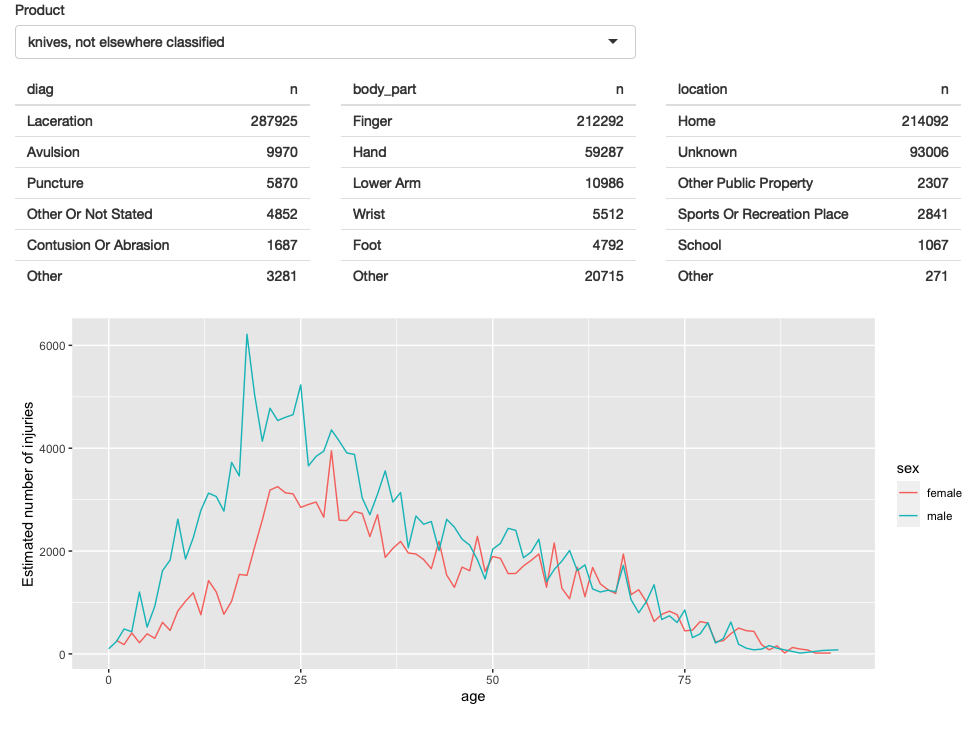
应用程序运行结果的屏幕截图如图4.4所示。您可以在https://github.com/hadley/mastering-shiny/tree/master/neiss/polish-tables.R中找到源代码,并在https://hadley.shinyapps.io/ms-polish-tables上试用该应用程序的实时版本。
4.6 发生率与计数
目前为止,我们只显示了一个图表,但我们希望用户可以选择显示受伤人数或标准化发生率。首先,我在用户界面中添加了一个控件。在这里,我选择使用selectInput(),因为它使两种状态都变得明确,并且将来很容易添加新的状态:
1 | fluidRow( |
(我默认选择发生率,因为我认为这样更安全;您不需要了解人口分布就可以正确解释图表。)
然后,我在生成图表时根据输入进行条件设置:
1 | output$age_sex <- renderPlot({ |
结果应用程序的屏幕截图如图4.5所示。您可以在https://github.com/hadley/mastering-shiny/tree/master/neiss/rate-vs-count.R中找到源代码,并在https://hadley.shinyapps.io/ms-rate-vs-count上试用该应用程序的实时版本。
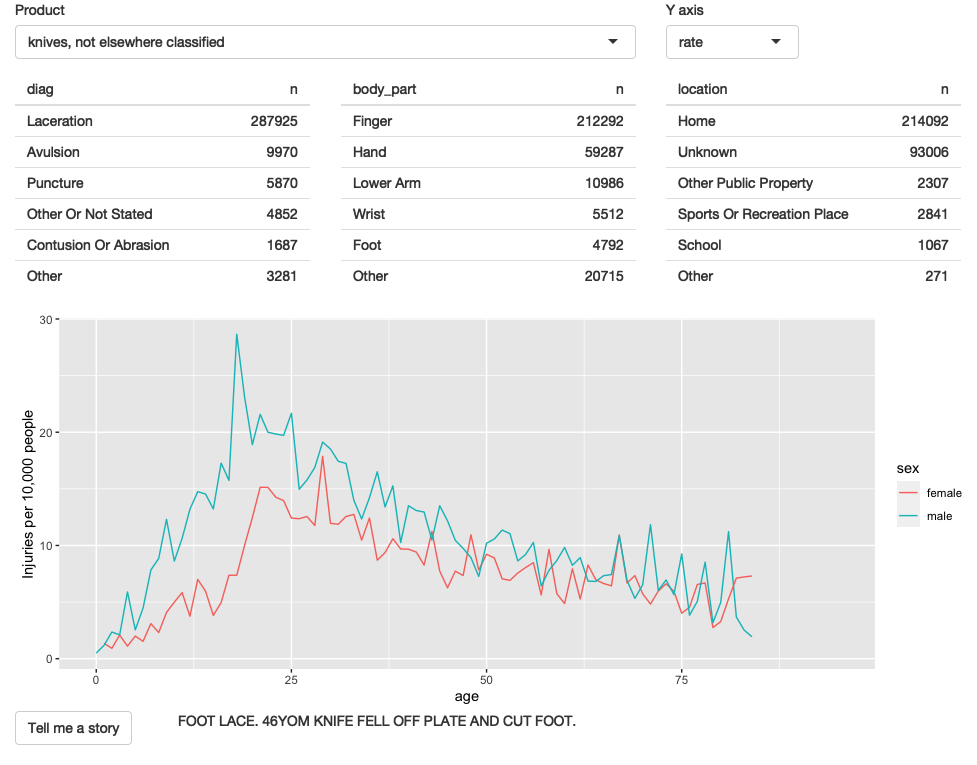
4.7 叙述
最后,我想提供一种方式来访问这些叙述,因为它们很有趣,而且它们提供了一种非正式的方式,可以在查看图表时检查你提出的假设。在R代码中,我同时采样多个叙述,但在你可以交互探索的应用程序中没有理由这样做。
解决方案分为两个部分。首先,我们在用户界面底部添加一行。我使用一个动作按钮来触发一个新的故事,并将叙述放在一个textOutput()中:
1 | fluidRow( |
然后,我使用eventReactive()创建一个反应,只有在按钮被点击或底层数据改变时才会更新。
1 | narrative_sample <- eventReactive( |
结果应用程序的屏幕截图如图4.6所示。您可以在https://github.com/hadley/mastering-shiny/tree/master/neiss/narrative.R中找到源代码,并在https://hadley.shinyapps.io/ms-narrative上试用该应用程序的实时版本。
4.8 练习
为每个应用程序绘制反应图。
在减少摘要表的代码中,如果将
fct_infreq()和fct_lump()翻转,会发生什么?添加一个输入控件,让用户决定在摘要表中显示的行数。
提供一种系统地使用前后按钮逐步浏览每个叙述的方法。
高级:使叙述列表“循环”,以便从最后一个叙述前进到第一个叙述。
4.9 总结
现在,您已经掌握了Shiny应用程序的基本知识,接下来的七章将为您提供一系列重要的技术。一旦您阅读了下一章关于工作流的章节,我建议您浏览其余章节以了解它们的涵盖内容,然后在需要应用程序技术时再回来阅读。
加关注
关注公众号“生信之巅”。
 |
 |
敬告:使用文中脚本请引用本文网址,请尊重本人的劳动成果,谢谢!



