
3 基础反应性
3.1 介绍
在Shiny中,您使用反应式编程来表达服务器逻辑。反应式编程是一种优雅而强大的编程范式,但起初可能会让人感到迷失,因为它与编写脚本的范式非常不同。反应式编程的关键思想是定义一个依赖图,这样当输入变化时,所有相关的输出都会自动更新。这使得应用程序的流程大大简化,但需要一段时间才能理解如何将所有内容整合在一起。
本章将为您提供对反应式编程的简单介绍,教授您Shiny应用中最常见的反应式结构的基本知识。我们将从服务器函数概览开始,更详细地讨论输入和输出参数的工作方式。接下来,我们将回顾最简单的反应形式(将输入直接连接到输出),然后讨论反应式表达式如何帮助您消除重复的工作。最后,我们将回顾一些新用户常见的障碍。
3.2 server函数
正如您所见,每个Shiny应用程序的内部如下所示:
1 | library(shiny) |
上一章介绍了前端的基础知识,ui对象包含向应用程序的每个用户呈现的HTML。ui很简单,因为每个用户都获得相同的HTML。server更复杂,因为每个用户都需要获得应用程序的独立版本;当用户A移动滑块时,用户B不应该看到他们的输出变化。
为了实现这种独立性,Shiny 在每次启动新会话时都会调用你的 server() 函数。就像其他任何 R 函数一样,当server函数被调用时,它会创建一个新的本地环境,该环境独立于该函数的每次其他调用。这使得每个会话都有一个唯一的状态,并隔离函数内创建的变量。这就是为什么你在 Shiny 中进行的几乎所有反应式编程都将在server函数内进行的原因。
server函数有三个参数:input、output和session。因为你永远不会自己调用服务器函数,所以你永远不会自己创建这些对象。相反,它们是由Shiny在会话开始时创建的,会话会返回到特定的会话。目前,我们将重点放在input和output参数上,而将session留到后面的章节。
3.2.1 输入
输入参数是一个类似列表的对象,其中包含从浏览器发送的所有输入数据,并根据输入ID命名。例如,如果您的UI包含一个输入ID为count的数字输入控件,如下所示:
1 | ui <- fluidPage( |
然后,您可以使用input$count访问该输入的值。它最初将包含值100,并随着用户在浏览器中更改值而自动更新。
与典型的列表不同,输入对象是只读的。如果您尝试在server函数内修改输入,将会出现错误:
1 | server <- function(input, output, session) { |
发生此错误是因为输入反映了浏览器中正在发生的事情,而浏览器是 Shiny 的“单一事实来源”。如果你能修改 R 中的值,你可能会引入不一致,其中输入滑块在浏览器中说了一件事,而 input$count 在 R 中说了不同的事情。这将使编程变得具有挑战性!稍后,在第 8 章中,您将学习如何使用 updateNumericInput() 之类的函数来修改浏览器中的值,然后 input$count 将相应地更新。
关于输入还有一件更重要的事情:它可以选择允许谁来读取它。要从输入中读取,你必须处于由 renderText() 或 reactive() 等函数创建的响应式环境中。我们很快就会回到这个想法,但这是一个重要的约束,它允许输出在输入更改时自动更新。这段代码说明了如果你犯了这个错误,你会看到的错误:
1 | server <- function(input, output, session) { |
3.2.2 输出
输出与输入非常相似:它也是一个根据输出ID命名的类似列表的对象。主要区别在于,您使用它来发送输出而不是接收输入。您总是将输出对象与渲染函数一起使用,如下面的简单示例:
1 | ui <- fluidPage( |
(请注意,ID在用户界面中被引用,但在服务器中没有引用——不加引号。)
渲染函数做了两件事:
它建立了一个特殊的反应式上下文,该上下文会自动跟踪输出所使用的输入。
它将您的R代码的输出转换为适合在网页上显示的HTML。
与输入一样,输出在使用上也是非常挑剔的。将会出现错误如果:
您忘记使用渲染函数
1
2
3
4
5
6server <- function(input, output, session) {
output$greeting <- "Hello human"
}
shinyApp(ui, server)
#> Error: Unexpected character object for output$greeting
#> ℹ Did you forget to use a render function?试图从输出中读取
1
2
3
4
5server <- function(input, output, session) {
message("The greeting is ", output$greeting)
}
shinyApp(ui, server)
#> Error: Reading from shinyoutput object is not allowed.
3.3 响应式编程
如果应用程序只有输入或只有输出,那么它将非常无聊。Shiny的真正魔力在于当您拥有同时具有两者的应用程序时。让我们看一个简单的例子:
1 | ui <- fluidPage( |
很难在书中展示这是如何工作的,但我在图3.1中尽力了。如果您运行应用程序并输入名称框,您会看到问候语会自动更新,就像您输入一样7。
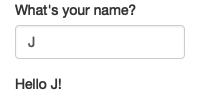
这是Shiny的一个核心概念:您不需要告诉输出何时更新,因为Shiny会自动为您解决。它是如何工作的呢?函数体中到底发生了什么?让我们更准确地思考服务器函数内部的代码:
1 | output$greeting <- renderText({ |
很容易将此理解为“将hello和用户名拼接在一起,然后将其发送到output$greeting”。但是这种思维模式在细微但重要的方面是错误的。仔细考虑一下:根据这种模型,您只发布一次指令。但是Shiny会在我们每次更新input$name时执行该操作,因此一定有更多的事情发生。
应用程序之所以能够工作,是因为代码并没有告诉Shiny创建字符串并将其发送到浏览器,而是告诉Shiny如果需要的话如何创建字符串。至于代码何时(甚至是否!)运行,这取决于Shiny。它可能早在应用程序启动时就开始运行,也可能稍后运行;可能多次运行,也可能永远不运行!这并不是说Shiny反复无常,只是说决定何时执行代码是Shiny的责任,而不是您的责任。将您的应用程序视为提供食谱给Shiny,而不是给它下命令。
3.3.1 命令式编程与声明式编程的区别
命令式编程和声明式编程是两种重要的编程风格,它们之间的区别在于:
在命令式编程中,您发出特定的命令并立即执行。这是您在分析脚本中习惯的编程方式:您命令R加载数据、转换数据、可视化数据并将结果保存到磁盘。
在声明式编程中,您表达了较高的目标或描述了重要的约束,并依靠其他人来决定如何以及/或何时将其转化为行动。这是您在Shiny中使用的编程风格。
使用命令式代码,您可以说“给我做个三明治”8。使用声明式代码,您可以表达“无论何时我打开冰箱,都要确保里面有一个三明治”。命令式代码是断言的;声明式代码是被动的。
大部分时间,声明式编程是非常自由的:您只需要描述您的整体目标,软件就会想出如何实现它们而无需进一步的干预。不利的一面是,偶尔您会确切地知道您想要什么,但您无法弄清楚如何以声明式系统理解的方式对其进行构架9。本书的目标是帮助您发展对底层理论的理解,以尽可能减少这种情况的发生。
3.3.2 懒惰
Shiny中声明式编程的优势之一是应用程序可以非常懒惰。Shiny应用程序只会做最少量工作来更新您当前可见的输出控件10。然而,这种懒惰有一个重要的缺点,您应该注意。你能找出下面server函数的问题吗?
1 | server <- function(input, output, session) { |
如果您仔细观察,您可能会注意到我写的是greting而不是greeting。在Shiny中,这不会产生错误,但不会实现您的期望。greting输出不存在,因此renderText()内部的代码永远不会被执行。
如果您正在开发Shiny应用程序,并且您就是无法理解为什么您的代码从未运行过,请仔细检查您的UI和服务器函数是否使用相同的标识符。
3.3.3 响应式图
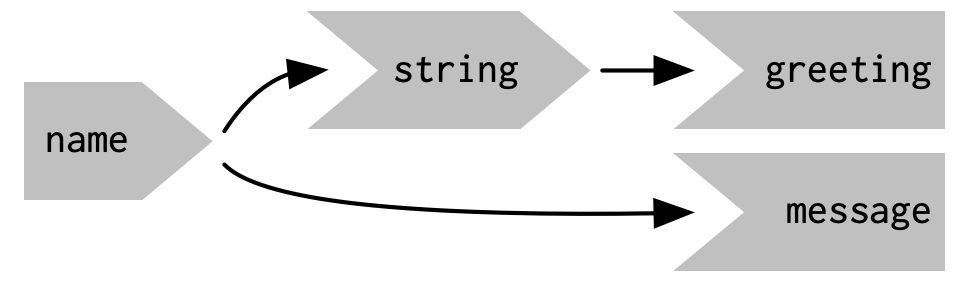
Shiny的懒惰性具有另一个重要属性。在大多数R代码中,您可以通过从上到下阅读代码来理解执行顺序。这在Shiny中不起作用,因为代码只在需要时才运行。要了解执行顺序,您需要查看响应式图,它描述了输入和输出之间的连接方式。上述应用程序的响应式图非常简单,如图3.2所示。
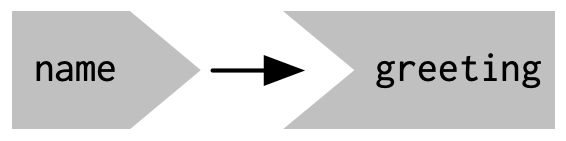
响应式图包含每个输入和输出的一个符号,并且我们将输入连接到输出,每当输出访问输入时。这个图告诉您greeting将需要重新计算,每当name被更改时。我们通常将这种关系描述为greeting对name具有反应依赖性。
注意我们为输入和输出使用的图形约定:name输入自然适合greeting输出。我们可以将它们紧密地排列在一起,如图3.3所示,以强调它们如何组合在一起;通常我们不会这样做,因为这只适用于最简单的应用程序。
响应式图中组件的形状表达了它们连接的方式。
 。
。
响应式图是一个强大的工具,用于理解您的应用程序如何工作。随着应用程序变得越来越复杂,快速高层次概述响应式图通常很有用,以提醒您所有组件如何组合在一起。在本书中,我们将通过显示响应式图来帮助您理解示例的工作原理,稍后在第14章中,您将学习如何使用reactlog,它将为您绘制图形。
3.3.4 反应式表达式
您将在响应式图中看到的另一个重要组件是反应式表达式。现在,您可以将其视为减少响应式代码重复的工具,通过在响应式图中引入额外的节点。
在我们的简单应用程序中,我们不需要反应式表达式,但我还是会添加一个,以便您可以了解它如何影响响应式图,如图3.4所示。
1 | server <- function(input, output, session) { |

反应式表达式接受输入并产生输出,因此它们具有结合输入和输出特征的形状。希望这些形状可以帮助您记住组件如何组合在一起。
3.3.5 执行顺序
了解代码的执行顺序是很重要的,因为执行顺序完全由响应式图决定。这与大多数R代码不同,在大多数R代码中,执行顺序由代码行的顺序决定。例如,我们可以翻转简单server函数中的两行代码的顺序:
1 | server <- function(input, output, session) { |
您可能会认为这会产生错误,因为output$greeting引用了尚未创建的响应式表达式string。但是请记住,Shiny是惰性的,因此只有在会话开始后,在string被创建后,才会运行该代码。
相反,此代码产生与上述相同的响应式图,因此代码运行的顺序完全相同。像这样组织代码对于人类来说很混乱,最好避免。相反,请确保响应式表达式和输出仅引用上面定义的内容,而不是下面。这将使您的代码更易于理解。
这个概念非常重要,与大多数其他R代码不同,因此我要再说一遍:响应式代码运行的顺序仅由响应图确定,而不是由其在服务器函数中的布局决定。
3.3.6 练习题
3.3.6.1 给定如下UI:
1 | ui <- fluidPage( |
修复下面三个服务器函数中的简单错误。首先尝试通过阅读代码发现问题;然后运行代码以确保你已修复它。
1 | server1 <- function(input, output, server) { |
3.3.6.2 绘制以下server函数的反应图:
1 | server1 <- function(input, output, session) { |
3.3.6.3 为何下述代码会失败?
1 | var <- reactive(df[[input$var]]) |
为什么 range() 和 var() 不是好的反应式命名?
3.4 反应表达式
我们已经在几个地方快速浏览了反应表达式,所以希望您已经了解了它们的作用。现在,我们将深入了解更多的细节,并说明为什么在构建真实应用程序时它们如此重要。
反应表达式之所以重要,是因为它们为Shiny提供了更多信息,以便在输入发生变化时减少重新计算,使应用程序更高效,并通过简化反应图来让人类更容易理解应用程序。反应表达式具有输入和输出的味道:
与输入类似,您可以在输出中使用反应表达式的计算结果。
与输出类似,反应表达式依赖于输入,并自动知道何时需要更新。
这种双重性意味着我们需要一些新的词汇:我将使用生产者来指代反应输入和表达式,而消费者则指代反应表达式和输出。图3.5用维恩图展示了这种关系。
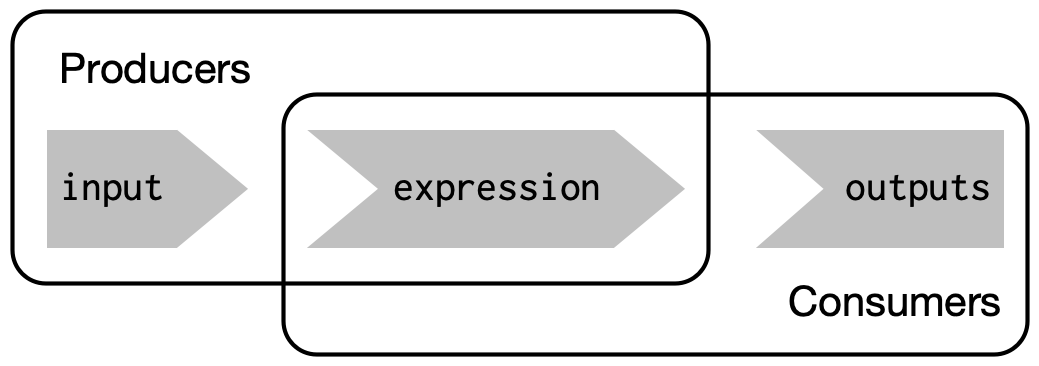
我们需要一个更复杂的应用程序来查看使用响应式表达式的优点。首先,我们将通过定义一些常规的R函数来为我们的应用程序提供支持,从而为我们的应用程序搭建舞台。
3.4.1 动机
假设我想用绘图和假设检验来比较两个模拟数据集。我做了一些实验,并提出了以下函数:freqpoly()用频率多边形12可视化两个分布,t_test()使用t检验来比较均值,并用字符串总结结果:
1 | library(ggplot2) |
:::primary 译者注
译者注:
这段代码中定义了两个函数,freqpoly和t_test。以下是它们的简单解释:
freqpoly函数:
这个函数是为了对比两个数据集x1和x2的分布。它首先将这两个数据集合并到一个数据框中,并为每个数据集分配一个组别”x1”和”x2”。然后,它使用ggplot2包的geom_freqpoly函数绘制频数多边形图,这个图能够展示数据的分布情况。binwidth参数决定了分箱的宽度,而xlim参数则设定了x轴的显示范围。t_test函数:
这个函数执行t检验,这是一种用于比较两组平均值是否有显著差异的统计检验方法。函数接受两个向量x1和x2作为输入,然后使用R的内置t.test函数执行t检验。然后,它使用sprintf函数以一种格式化的方式返回结果,包括p值以及95%置信区间。注意:在这段代码中,
sprintf函数用于格式化输出字符串。”%0.3f”表示浮点数,保留3位小数;”[%0.2f, %0.2f]”表示浮点数,保留2位小数,用于显示置信区间。
:::
如果我有一些模拟数据,我可以使用这些函数来比较两个变量:
1 | x1 <- rnorm(100, mean = 0, sd = 0.5) |
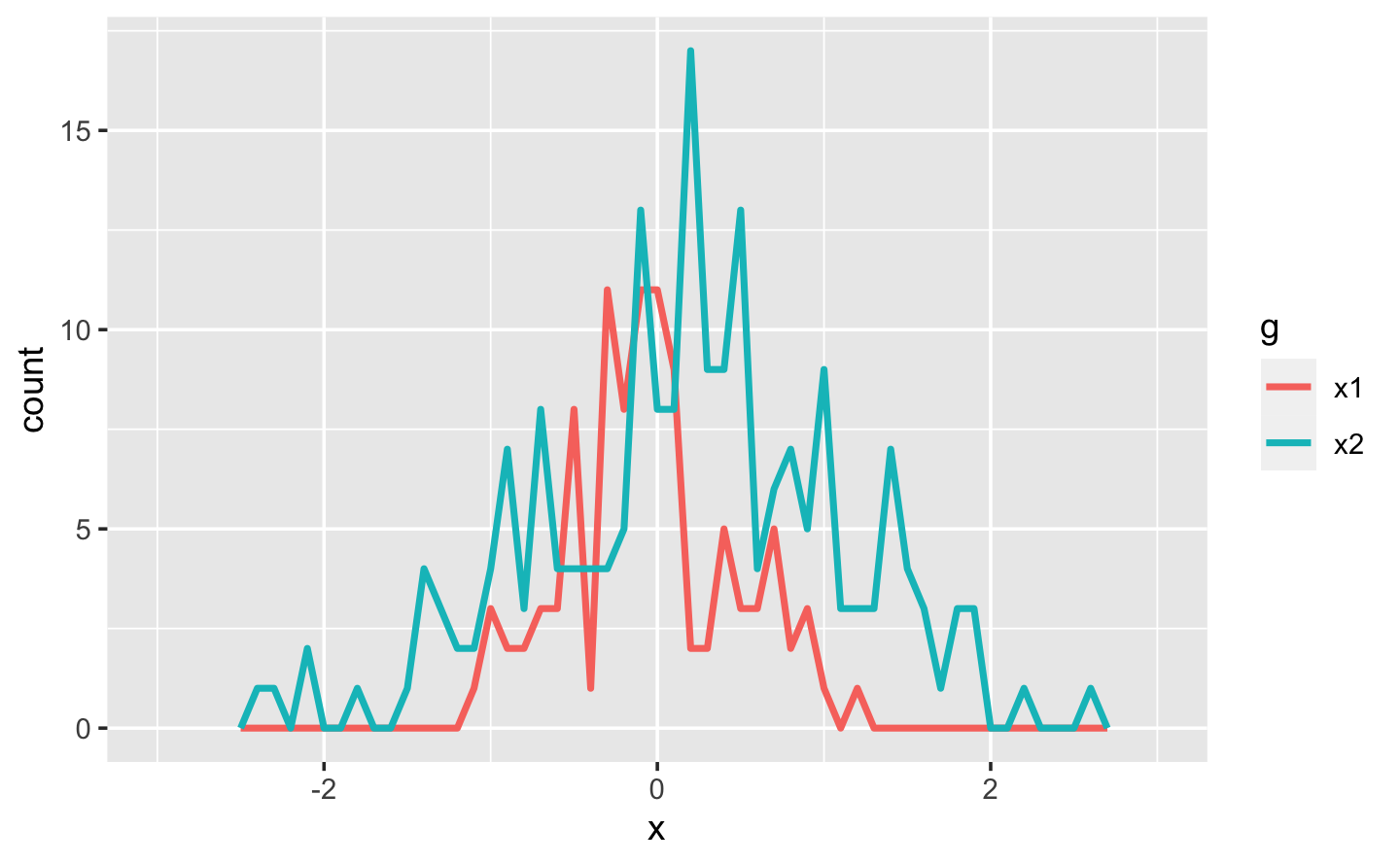
在真正的分析中,你可能在完成这些函数之前已经做了一堆探索。我在这里跳过了这个探索,这样我们就可以尽快地进入应用程序。但是将命令式代码提取到常规函数中是所有Shiny应用程序的一项重要技术:你从应用程序中提取的代码越多,就越容易理解。这是很好的软件工程,因为它有助于隔离问题:应用程序外的函数专注于计算,这样应用程序内的代码就可以专注于响应用户操作。我们将在第18章再次回到这个想法。
3.4.2 应用程序
我想使用这两个工具快速探索一系列模拟。Shiny应用程序是一种很好的方法,因为它可以让你避免繁琐地修改和重新运行R代码。下面我将这些部分打包成一个Shiny应用程序,在这里我可以交互式地调整输入。
让我们从UI开始。我们将在第6.2.3节中详细介绍fluidRow()和column()的作用;但是你可以从它们的名字中猜出它们的目的。第一行有三个用于输入控件的列(distribution 1、distribution 2和绘图控件)。第二行有一个宽列用于绘图,一个窄列用于假设检验。
1 | ui <- fluidPage( |
server函数从指定的分布中抽取后,结合了freqpoly()和t_test()函数的调用:
1 | server <- function(input, output, session) { |
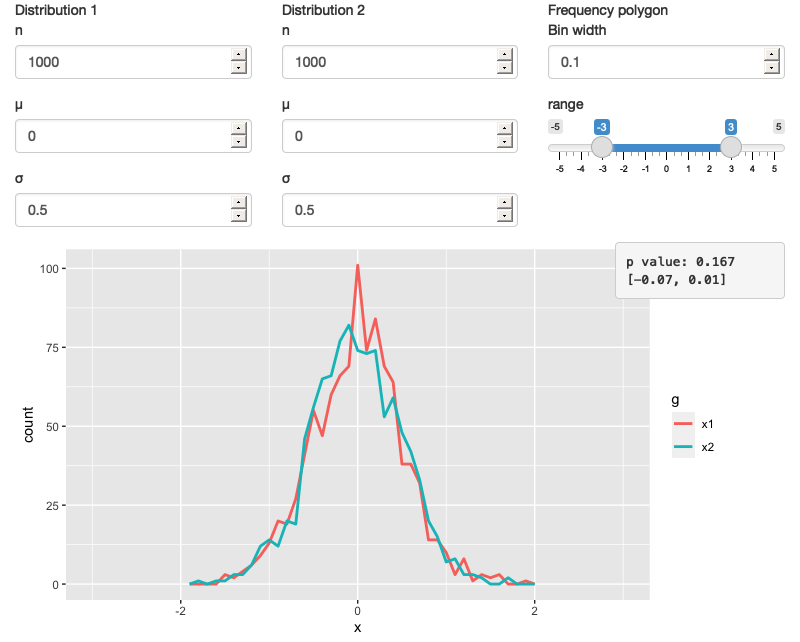
这段定义服务器和用户界面的内容产生了图3.6。你可以在https://hadley.shinyapps.io/ms-case-study-1找到它的活跃版。我推荐你打开应用程序并进行快速操作,以确保在继续阅读之前理解其基本操作。
3.4.3 反应式图表
让我们开始绘制这个应用程序的反应式图表。Shiny足够智能,仅在引用的输入发生更改时更新输出;它不够智能,不能仅选择性地运行输出内部的代码片段。换句话说,输出是原子的:它们要么整体执行,要么不执行。
例如,以下是从server中获取的代码片段:
1 | x1 <- rnorm(input$n1, input$mean1, input$sd1) |
作为阅读此代码的人,你可以看出我们只需要在n1、mean1或sd1发生变化时更新x1,在n2、mean2或sd2发生变化时更新x2。然而,Shiny只将输出视为一个整体,因此每当n1、mean1、sd1、n2、mean2或sd2中的一个发生变化时,它都会更新x1和x2。这导致了图3.7所示的反应图。
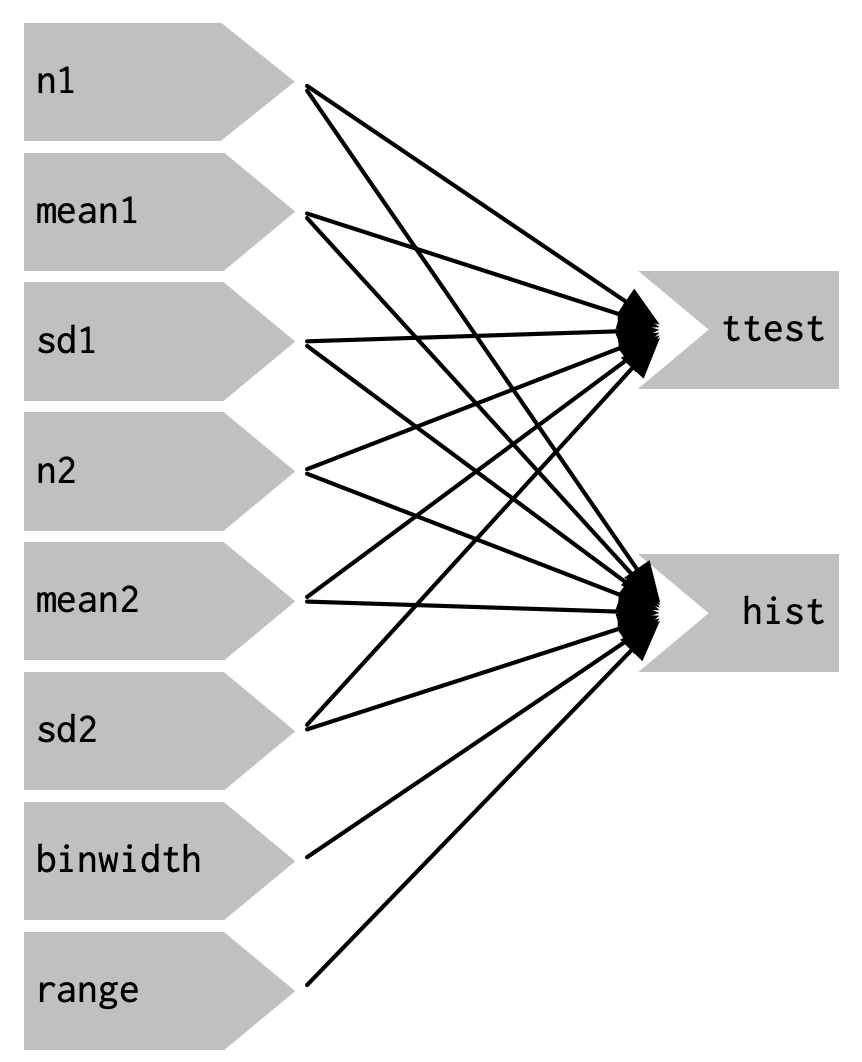
你会注意到,图中非常密集:几乎每个输入都直接连接到每个输出。这造成了两个问题:
应用程序难以理解,因为有太多的连接。您无法将应用程序的任何部分单独拉出来进行分析。
应用程序效率低下,因为它做了很多不必要的工作。例如,如果您更改了图的断点,将重新计算数据;如果您更改了n1的值,将更新x2(在两个地方!)。
应用程序还有一个其他主要缺陷:频率多边形和t检验使用单独的随机抽样。这可能会误导,因为您期望它们在同一基础数据上工作。
幸运的是,我们可以通过使用反应式表达式来提取重复的计算,从而解决所有这些问题。
3.4.4 简化图表
在server函数中,我们将现有代码重构为两个新的反应式表达式x1和x2,它们模拟来自两个分布的数据。要创建反应式表达式,我们调用reactive()并将结果分配给一个变量。要稍后使用该表达式,我们将变量称为函数进行调用。
1 | server <- function(input, output, session) { |
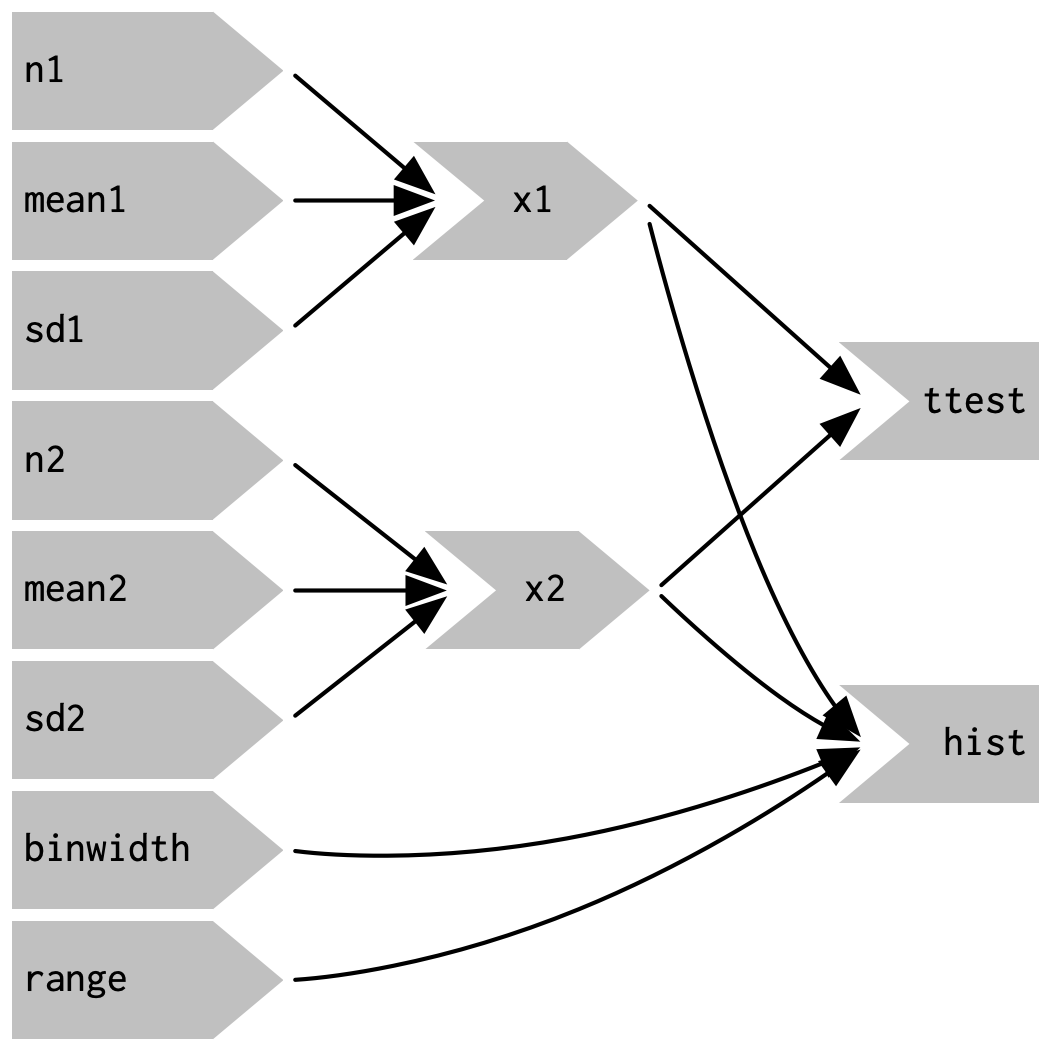
这种转换产生了图3.8所示的实质上更简单的图表。这个更简单的图表使得应用程序更容易理解,因为您可以将连接组件分开理解;分布参数的值只会通过x1和x2影响输出。这种重写还使应用程序更高效,因为它减少了大量的计算。现在,当您更改binwidth或range时,只有图表发生变化,而不是基础数据。
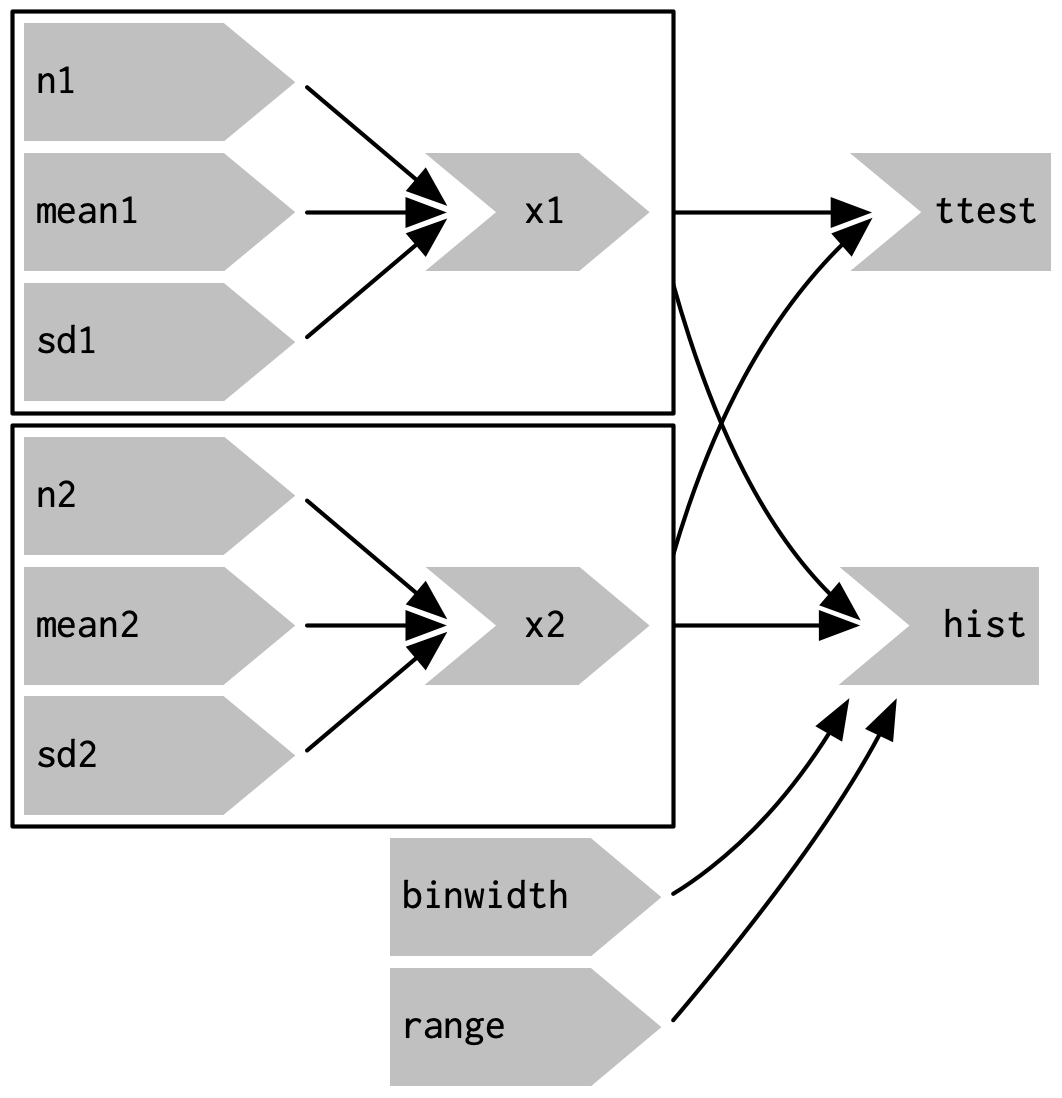
为了强调这种模块化,图3.9在独立组件周围画了框。我们将在第19章讨论模块时回到这个想法。模块允许您提取重复的代码以进行重用,同时保证其与应用程序中的其他所有内容隔离。对于更复杂的app,模块是一种非常有用且强大的技术。
您可能熟悉编程中的“三次规则”:无论何时您复制和粘贴某些内容三次,您应该想办法减少重复(通常通过编写函数)。这是很重要的,因为它减少了代码中的重复量,使代码更容易理解,并且随着您的需求变化而更容易更新。
然而,我认为在Shiny中,您应该考虑“一次规则”:无论何时您复制和粘贴某些内容一次,您应该考虑将重复的代码提取到反应式表达式中。对于Shiny来说,这个规则更加严格,因为反应式表达式不仅使人类更容易理解代码,而且也提高了Shiny有效地重新运行代码的能力。
3.4.5 我们为什么需要反应式表达式?
当您刚开始使用反应式代码时,您可能会想知道为什么我们需要反应式表达式。您为什么不使用现有的工具来减少代码中的重复:创建新变量和编写函数?不幸的是,这两种技术在反应式环境中都不起作用。
如果您尝试使用变量来减少重复,您可能会编写类似这样的代码:
1 | server <- function(input, output, session) { |
如果您运行此代码,则会收到错误,因为您尝试在反应式上下文之外访问输入值。即使您没有收到该错误,您仍然会遇到问题:x1和x2只会在会话开始时计算一次,而不是每次输入之一更新时都会计算。
如果您尝试使用函数,则应用程序将工作:
1 | server <- function(input, output, session) { |
但它与原始代码有同样的问题:任何输入都会导致所有输出被重新计算,并且t检验和频率多边形将在单独的样本上运行。响应式表达式会自动缓存其结果,并且仅在输入更改时才进行更新13。
变量只计算一次值(粥太凉了),函数在每次调用时计算值(粥太烫了),而响应式表达式只在值可能发生变化时计算值(粥刚刚好!)。
3.5 控制评估时间
现在你已经熟悉了反应性的基本概念,我们将讨论两种更高级的技术,它们可以让你增加或减少反应性表达式的执行频率。在这里,我将展示如何使用基本技术;在第15章中,我们将回到它们的底层实现。
为了探索基本思想,我将简化我的模拟应用程序。我将使用只有一个参数的分布,并强制两个样本共享相同的n。我还将删除绘图控件。这将产生更小的UI对象和server功能:
1 | ui <- fluidPage( |
这生成了如图3.10所示的应用程序和如图3.11所示的反应图。
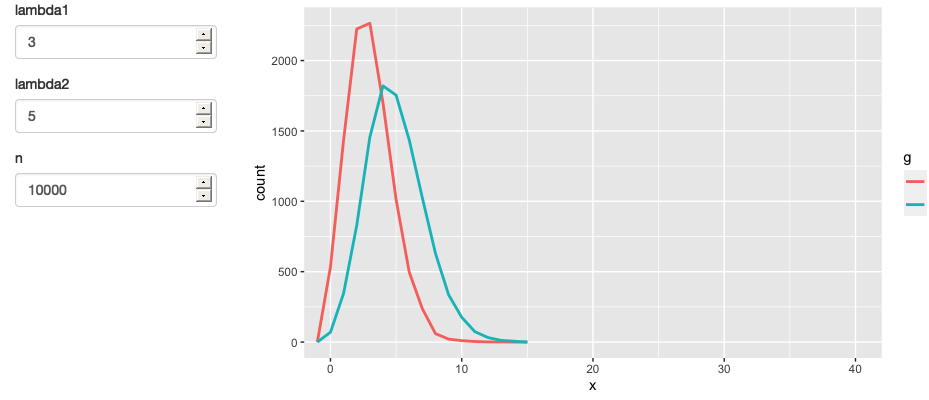
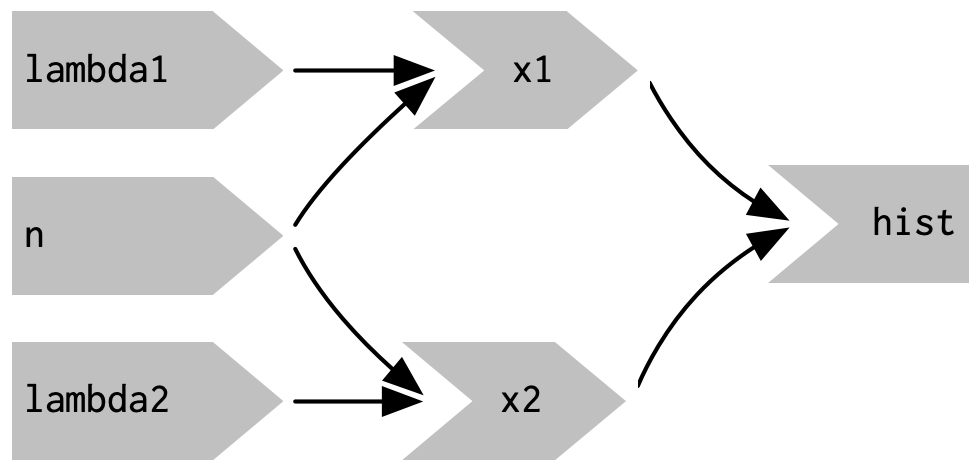
3.5.1 定时失效
想象一下,如果你想通过不断重新模拟数据来强调这是模拟数据的事实,以便你看到动画而不是静态图14。我们可以使用新的函数:reactiveTimer()来增加更新的频率。
reactiveTimer()是一个反应式表达式,它依赖于一个隐藏的输入:当前时间。当您想要一个反应式表达式比其他方式更频繁地使自己无效时,您可以使用reactiveTimer()。例如,以下代码使用500毫秒的间隔,这样图将每两秒钟更新一次。这足够快,以提醒你正在查看模拟,而不会因快速变化而使你眼花缭乱。这一变化产生了如图3.12所示的反应图。
1 | server <- function(input, output, session) { |
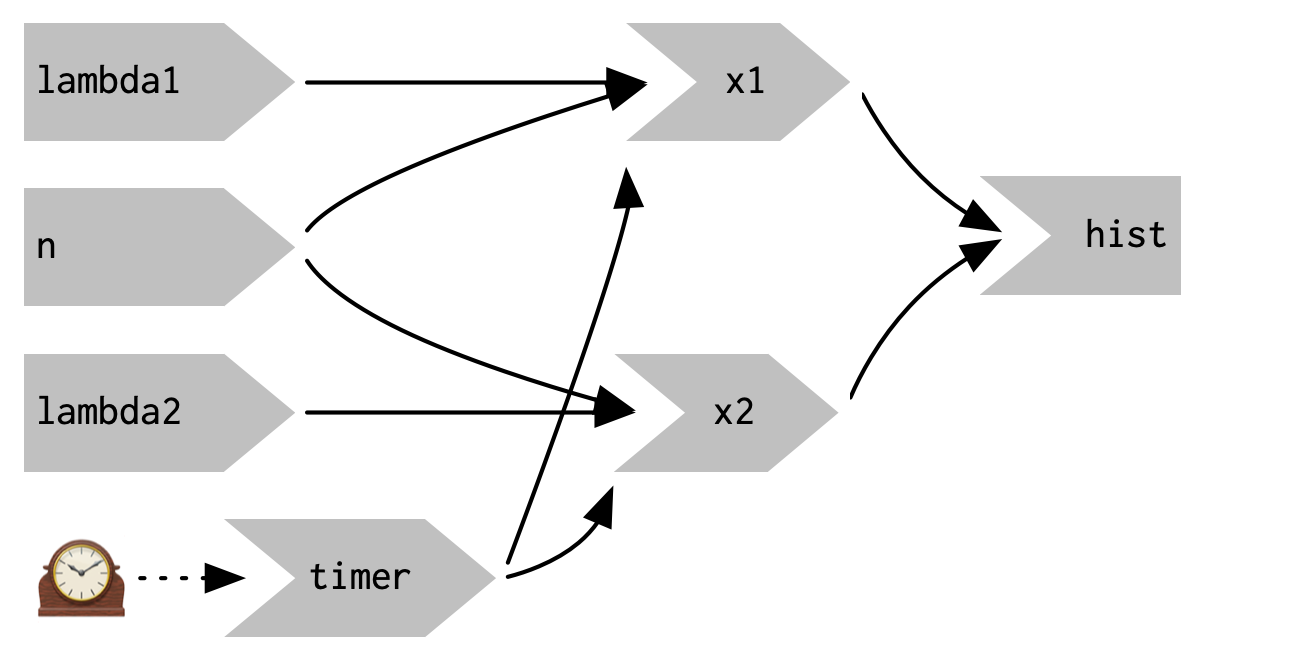
注意我们在计算x1()和x2()的反应式表达式中使用timer()的情况:我们调用它,但不使用它的值。这使得x1和x2可以对timer产生反应式依赖,而不必担心它返回的确切值。
3.5.2 点击事件
在上述场景中,想象一下如果模拟代码需要1秒钟才能运行完会发生什么情况。我们每0.5秒执行一次模拟,所以Shiny会有越来越多的工作要做,而且永远无法追赶上来。同样的问题也可能发生在如果有人在您的应用程序中快速点击按钮,而您正在进行的计算相对昂贵的情况下。这可能会给Shiny创建大量的后台工作,当Shiny忙于处理这些后台工作时,它无法响应任何新的事件,从而导致用户体验不佳。
如果这种情况发生在您的应用程序中,您可能希望要求用户选择执行昂贵的计算,要求他们点击一个按钮。这是actionButton()的一个很好的用例:
1 | ui <- fluidPage( |
要使用操作按钮,我们需要学习一种新工具。为了理解原因,让我们首先使用与上述相同的方法来解决这个问题。与上面一样,我们提到simulate但不使用它的值来对其产生反应式依赖。
1 | server <- function(input, output, session) { |
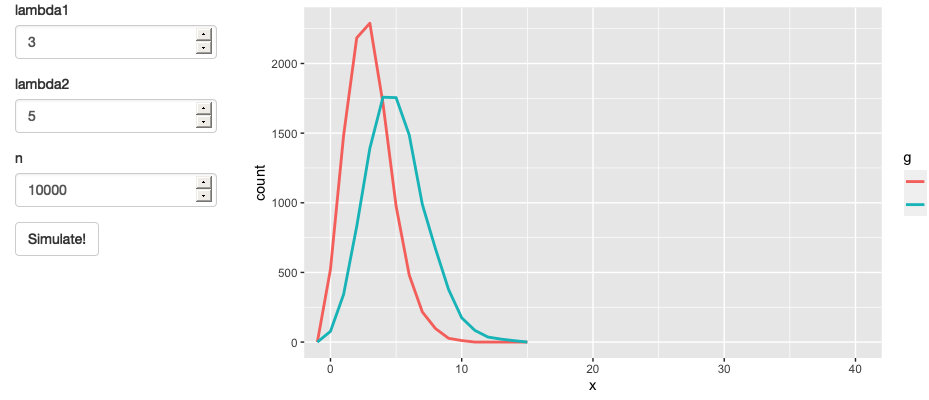
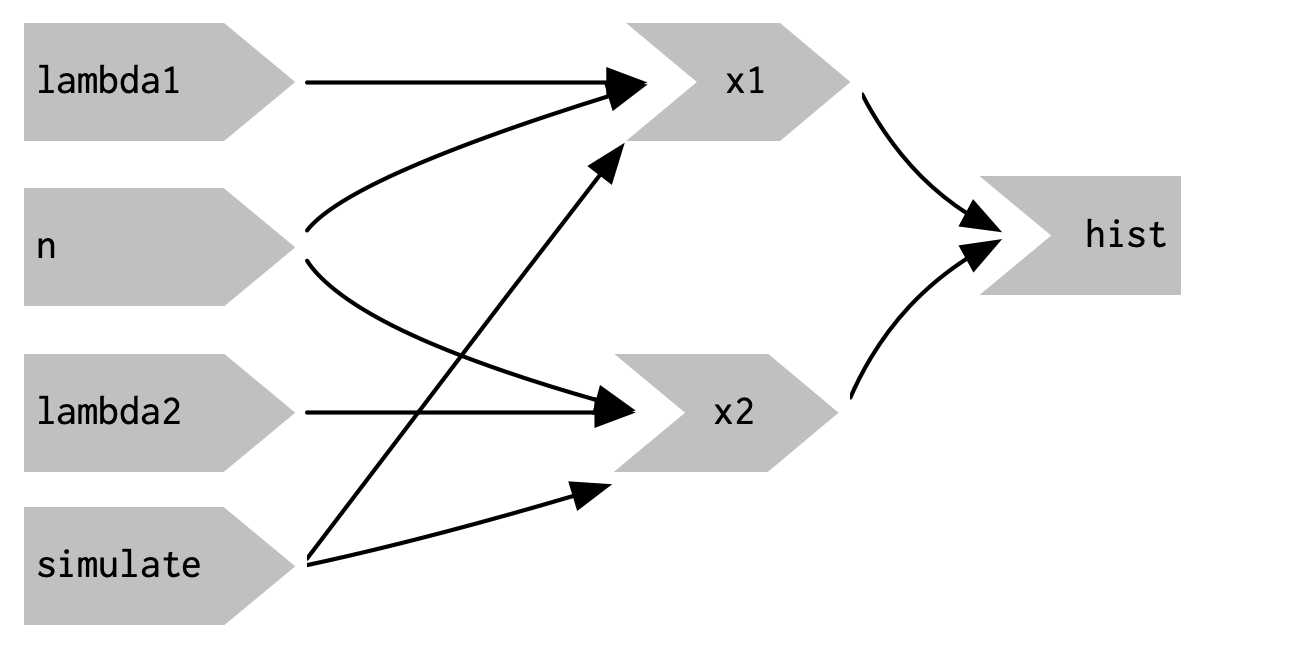
这产生了图3.13的应用程序和图3.14的反应图。这没有达到我们的目标,因为它只是引入了一个新的依赖项:当我们点击simulate按钮时,x1()和x2()将更新,但它们将继续在lambda1、lambda2或n改变时更新。我们希望取代现有的依赖项,而不是增加新的依赖项。
为了解决这个问题,我们需要一个新的工具:一种使用输入值而不产生反应式依赖的方法。我们需要eventReactive(),它有两个参数:第一个参数指定要对其产生依赖的参数,第二个参数指定要计算的内容。这让应用程序只有在simulate被点击时才计算x1()和x2():
1 | server <- function(input, output, session) { |
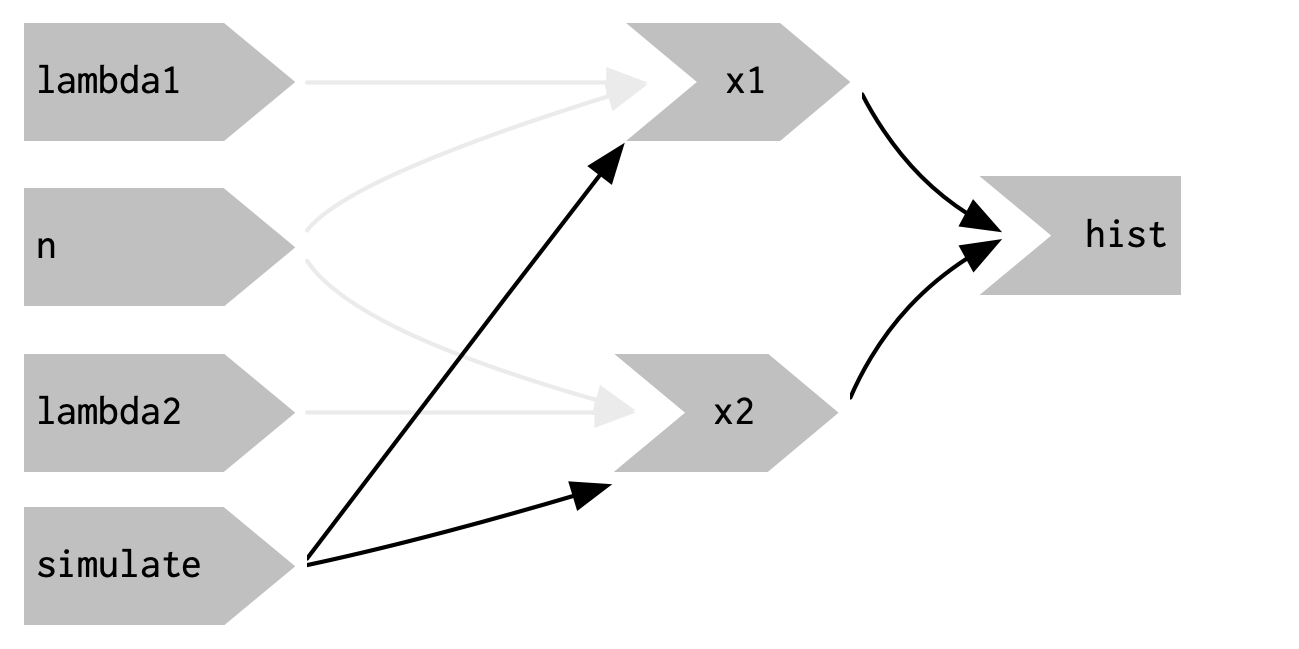
图3.15显示了新的反应图。请注意,如所期望的那样,x1和x2不再对lambda1、lambda2和n产生反应式依赖:改变它们的值不会触发计算。我保留了浅灰色的箭头,只是为了提醒您x1和x2继续使用这些值,但不再对其产生反应式依赖。
3.6 观察者
到目前为止,我们一直关注应用程序内部发生的事情。但有时,您需要将应用程序外部的某些操作与应用程序内部的操作关联起来,以在其他地方产生副作用。这可能是将文件保存到共享网络驱动器、向Web API发送数据、更新数据库,或者(最常见)是在控制台上打印调试消息。这些操作不会影响应用程序的外观,因此您不应该使用输出和渲染函数。相反,您需要使用观察者(observer)。
有多种创建观察者的方法,我们将在第15.3节中讨论它们。现在,我想向您展示如何使用observeEvent(),因为它在您学习Shiny时为您提供了一个重要的调试工具。
observeEvent()与eventReactive()非常相似。它有两个重要的参数:eventExpr和handlerExpr。第一个参数是输入或表达式,对其产生依赖;第二个参数是执行的代码。例如,对server()进行以下修改意味着每当name被更新时,都会向控制台发送一条消息:
1 | ui <- fluidPage( |
observeEvent()和eventReactive()之间有两个重要的区别:
您不需要将
observeEvent()的结果分配给一个变量,因此您不能从其他反应式消费者中引用它。
观察者和输出密切相关。您可以将输出视为具有特殊副作用:更新用户浏览器中的HTML。为了强调这种紧密关系,我们将在反应图上以相同的方式绘制它们。这产生了如图3.16所示的反应图。
3.7 总结
本章应有助于您更好地了解Shiny应用程序的后端,即响应用户操作的server()代码。您还初步掌握了支撑Shiny的响应式编程范式。在这里您所学到的东西将会对您大有帮助;我们将在第13章中回到底层理论。响应式编程非常强大,但它与您最习惯的R编程命令式风格截然不同。如果需要一段时间才能理解所有后果,请不要感到惊讶。
本章结束了我们对Shiny基础的概述。下一章将通过创建一个更大的Shiny应用程序来帮助您练习迄今为止所学的材料,该应用程序旨在支持数据分析。
关注
关注公众号“生信之巅”。
 |
 |
敬告:使用文中脚本请引用本文网址,请尊重本人的劳动成果,谢谢!



